











The 15% Rule: Why Most of Your LLM is Dead Weight


The industry has long been fixated on one metric in the competition to create the most potent Large Language Models (LLMs): parameter count. As though they were neurons in the human brain, we speak in trillions of weights. However, an increasing amount of data from Microsoft Research and the ACM Digital Library indicates that we have been creating "behemoths" that are essentially ineffective.
The truth? Your model is probably only using 15% of its brain for any given task, such as debugging a Python script or summarizing a lecture. The remaining 85% is "dead weight," using a lot of GPU memory and power without adding anything to the output.
The Brute Force Inference: The Engineering Bottleneck
In order to generate the next token, the standard transformer architecture requires a pass through almost every weight in the model each time you hit "enter" on a prompt. In a recent article titled "A Hybrid Future for AI" in Communications of the ACM (CACM), researchers pointed out that this "dense" computation is the main cause of the exponential rise in AI cooling and energy costs.
Running a dense LLM today is computationally equivalent to sending your entire class through the Pattanagere metro exit crowd at 9:00 AM in order to find a single ID card that you dropped on your way out. You are footing the bill for more than sixty people's commute when just one was enough for the job!
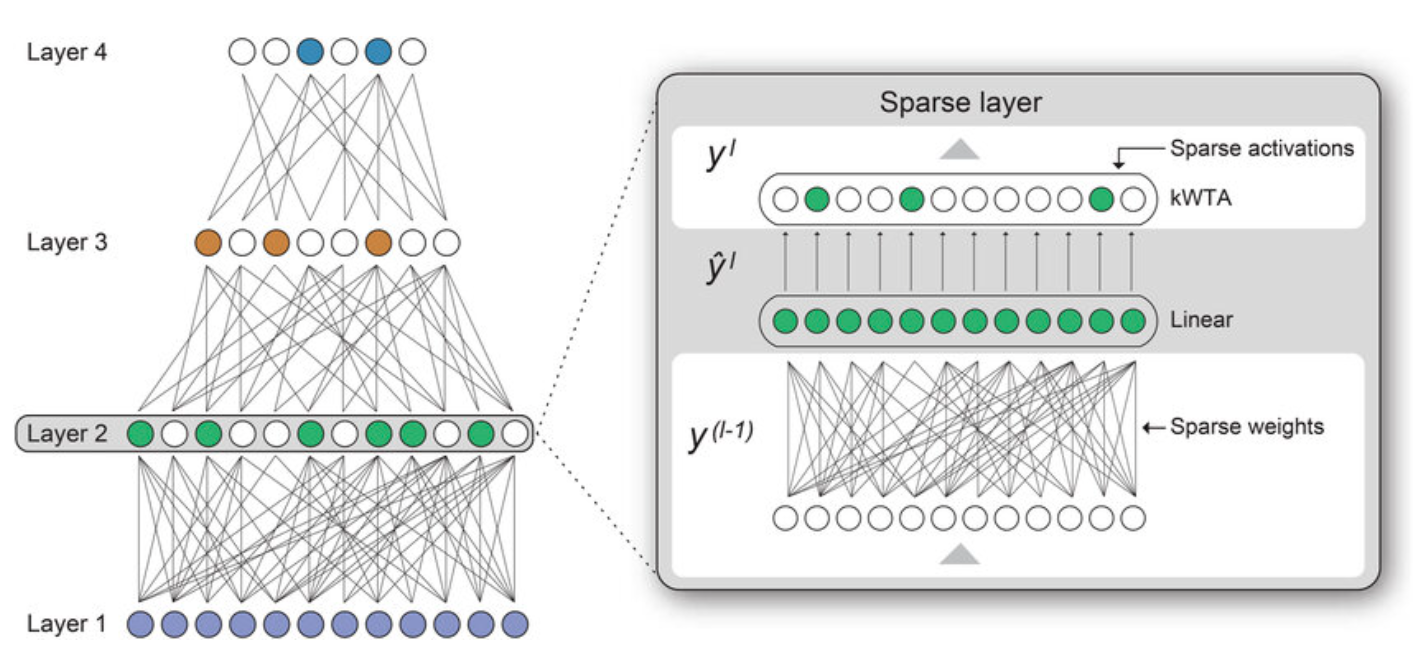
Figure 1: Comparison of a dense network vs. a sparse network where only active pathways are utilized.
Trimming the Fat: The Core ML Strategy
The top research facilities in the world are now switching from "Bigger is better" to "Compact AI" as described by ACM fellow Tim Menzies. The major players are surgically eliminating the dead weight in the following ways:
1. SparseGPT, Google's "One-Shot" Surgery
SparseGPT, a breakthrough in Weight Pruning, was created by Google Research and IST Austria. In the past, eliminating weights required costly retraining for weeks. SparseGPT prunes a model by 60% in a single shot (less than 4.5 hours) with nearly no accuracy loss using a mathematical shortcut called the Hessian inverse.
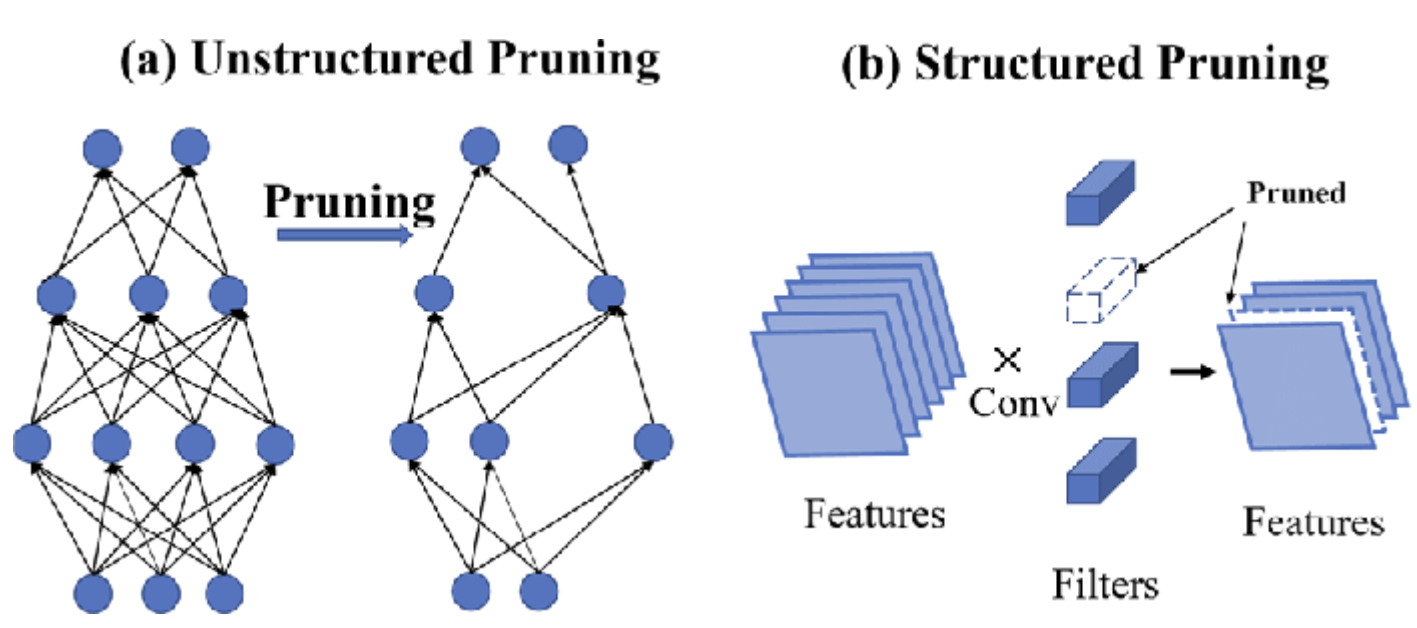
Figure 2: Structured vs. Unstructured pruning techniques used to optimize hardware performance.
2. Reinforced Context Pruning (CoT-Influx) from Microsoft
Microsoft uses a different strategy called Contextual Sparsity. Their CoT-Influx research focuses on pruning the thought process rather than permanently removing weights. They enable smaller models to outperform GPT-4 by simply being more compact by recognizing and turning off redundant reasoning paths in a chain-of-thought prompt.
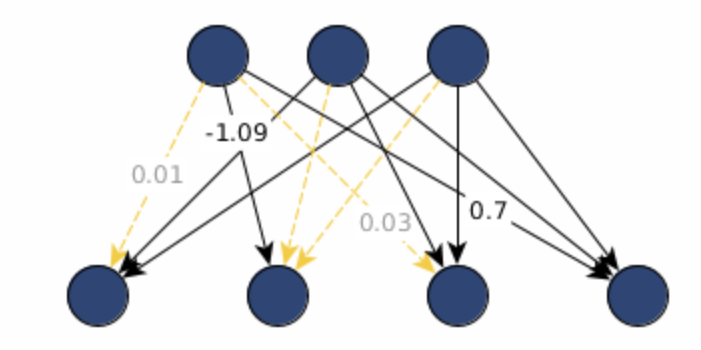
Figure 3: A weight magnitude heatmap showing the distribution of near zero "dead" weights.
3. "Concept Mapping" by Anthropic (Sparse Autoencoders)
Mechanistic Interpretability has replaced Anthropic. They have mapped concept clusters (such as "ACM Blogs" or "C++ Code") to particular neurons using Sparse Autoencoders (SAEs). This enables Surgical Pruning, which eliminates whole groups of unrelated information from a specialized model without the need for guesswork.
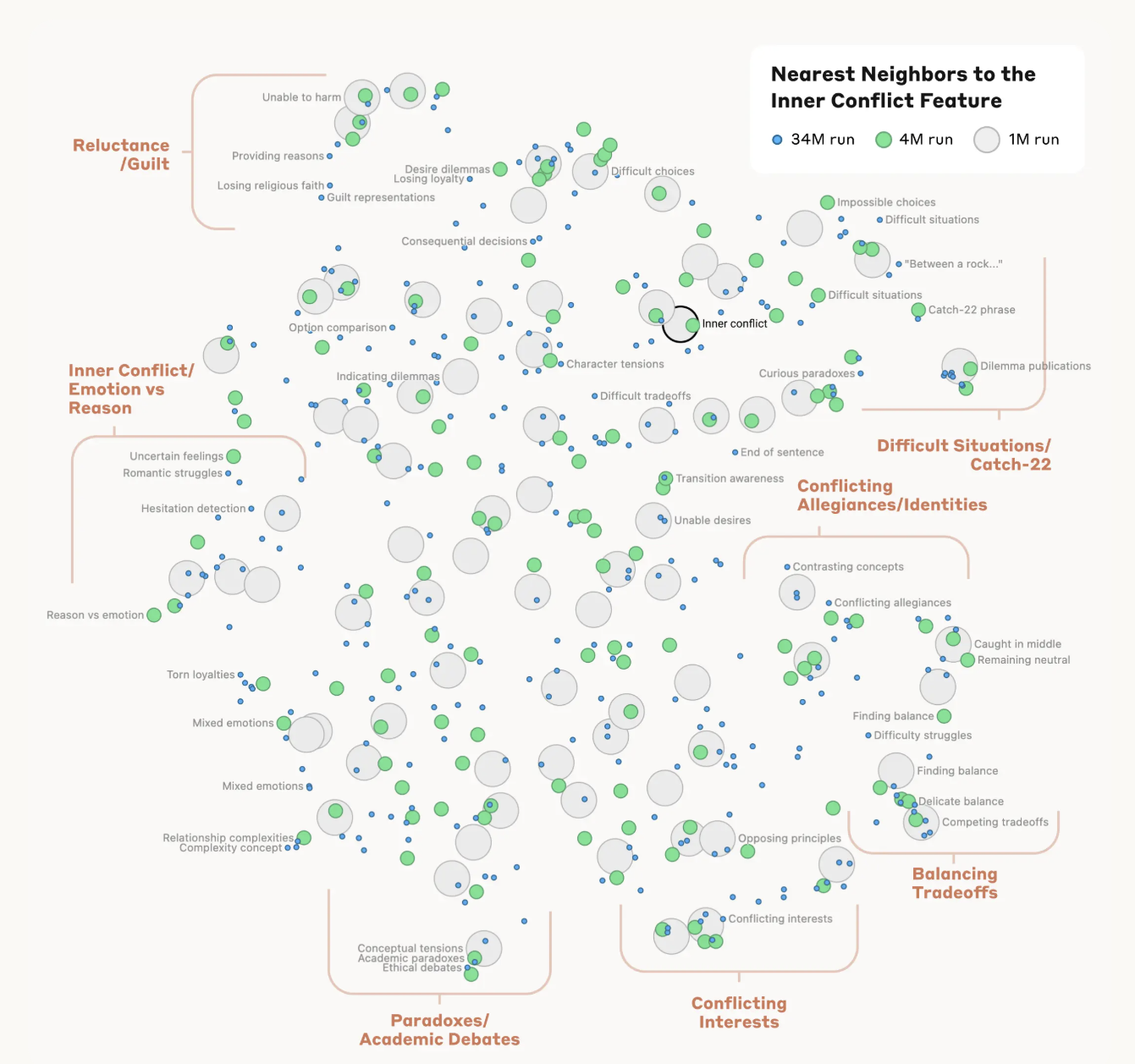
Figure 4: Concept clusters mapped using Sparse Autoencoders to visualize model "features."
The Matthew Effect: The Risk of the 15% Rule
As student engineers, we need to consider the catch. A 2025 ACM TechBrief warns about the Matthew Effect in Pruning. When we reduce models, they remain accurate for common data, such as English text. However, the accuracy declines sharply for minority data, like niche languages or specialized technical terms. The 85% we discard may seem unimportant for most, but it holds the rare knowledge that makes AI truly universal.
In conclusion, efficiency is the new intelligence.
The scaling law era is already giving way to the efficiency era. Our objective as engineers is now to create systems that are contextually aware of their own size rather than merely deploying the largest model feasible. Elastic models, i.e. architectures that can function as 175B-parameter experts for a complicated dissertation while shrinking to a 1B-parameter mini for a straightforward chat are the way of the future.
True intelligence after all is more about how many parameters you can afford to leave behind than it is about how many you possess.
References:
- ACM TechNews: "A Hybrid Future for AI"
- Google/IST Austria: "SparseGPT: Massive Models accurately pruned in one-shot"
- Microsoft Research: "Fewer is More: Reinforced Context Pruning"